Langsmith Editorの詳しい使い方はこちら です。
また実際の使い方については、こちらのスライド にも掲載しております。
Langsmith Editor
この記事では、Langsmith Editor の使い方 (コツ) と技術について、簡単に説明していきます。Langsmith Editorは英語論文執筆に特化したライティング支援システムです。現在のシステムは自然言語処理の論文データを活用して学習されているため、自然言語処理や情報科学の論文の執筆に向いています。開発者 (この記事を書いている人) が所属している乾研究室 でも、論文執筆時に活用されています。
せっかくなので、私達が論文執筆時によく活用する他のツールにも触れていき、英語執筆経験の浅い学生などが英語論文を書くときの参考としても、本記事が助けになれば幸いです。
ライティング支援
英語論文執筆に限らず、(良い・魅力的な) 文章を書くには、ある程度の時間と労力を要すると思います。
文章を完成させる上では、少なくとも書く内容(what to say)と、書き方・伝え方(how to say)という2つの側面で質を要求されるでしょう。例えば、第二外国語で文章を書く際には「書きたい内容はまとまっているけど、うまい表現が見つからない」という状況が考えられます。本システムの目標は、そのような書き方・伝え方に躓いている書き手を支援することです。
現在公開中のデモ (https://editor.langsmith.co.jp/) では、英語論文執筆支援を見据えています。英語で情報を発信していくことが強いられる国際競争の中で、言語的に不利な日本の学生や研究者を支援することは重要であると考えています。今後さらに分野や用途を拡大していきます。是非、皆様の状況に照らし合わせて読んでみてください。
使って欲しい場面
何か特定の状況(論文執筆、メール、チャットなど)で英語を書く状況を考えてみましょう。いい状況が思いつかなかった方は、フォーマルな場面(英語論文など)において、「場面を問わず、良い・魅力的な文章を書くことには、時間と労力を消費すると思います。」という文を英語で書く場面を想像してみましょう。
良い英語の表現が思いつかない時には、辞書を使ったり、グーグルで調べたり、機械翻訳システムを用いたりするなど、何かツールを用いるのではないでしょうか。ここでは例として、翻訳システムDeepL を使ってみましょう。

とりあえず初稿と呼べそうな文が手に入りましたね。ところで、この初稿をほぼそのまま (例えば) 論文に書こうという気持ちになるでしょうか?
多くの方は次のステップとして、「本当にこういう表現が論文で使われるのか?」や、メールの文面であれば「本当にこれは失礼な表現でないか?」という確認・推敲を行うのではないかと思います。このような推敲にはしばしば労力がかかります。
ここでLangsmith Editor が役立ちます。
エディターがいくつか修正案を出してくれました。例えば、主語は”We”の方が良い、”a lot of”より”a great deal of “の方が良いと言っています。特に前者は、論文の筆者はたいてい1人ではないため、我々の感覚にあっています。このように特定の場面 (現在は論文執筆)に特化し、流暢さや文体などの一歩踏み込んだ提案を行います。
書き手が真に書きたいことを超能力のように当てることは非常に難しいので、本システムは様々な修正案を提示し、どのような修正を行うかの最終判断は書き手に委ねています。書き手が気づかなかったミスや側面に意識を向けさせることができればと考えています。
また、このような書き方を模索する段階でGrammarly などのエラーチェッカーを用いる方もいると思いますが、これらのシステムはスペルや文法に関する明らかなエラーを直す (体裁を整える) 側面が強い印象です。そのため、推敲の初期段階のような、より良い書き方や伝え方を模索する段階よりも、原稿の完成に近い段階で用いるのが良いと考えています。例えば、上と同じ文を入力しても、文法的には問題がないため、特にフィードバックはしてくれません。

まとめると、一例として、こんな工程を踏むとスムーズに英語がかけるかもしれません。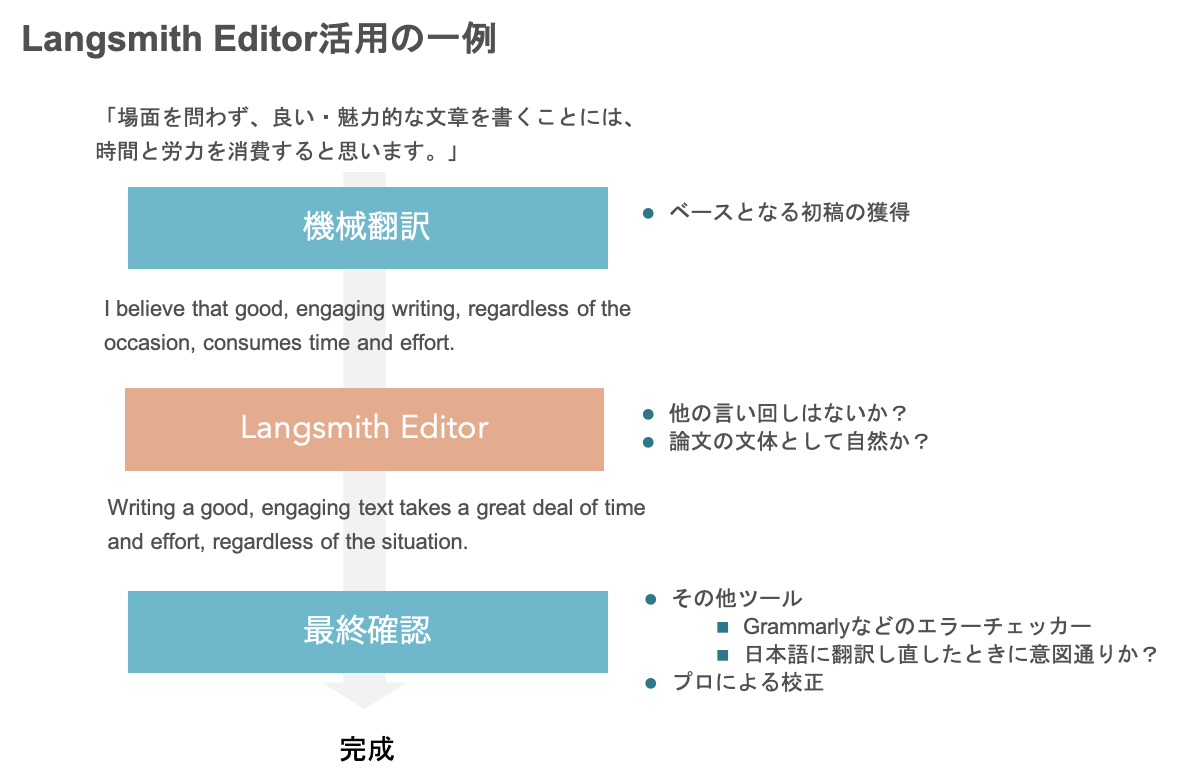
英語論文執筆という文脈では、最後に英文校正に投げたり、指導教員に添削を依頼したりすることも多いと思うので、その前段階でそこまで質を気にしなくていいやと考えている人がもしかしたらいるかもしれません。しかし、添削に出した段階の文章の質で、得られるフィードバックの質も変わると思います (あくまで経験的に感じているだけですが)。例えば、高いお金を払って文法ミスがたくさんある原稿を校正業者に出し、文法チェッカーでも同定できるようなミスをたくさん訂正してもらうのはもったいないです。英文校正業者に払うお金や指導教員が使える時間といった限られたリソースを最大限活用するためにも、是非Langsmith Editorを使いながら、効率的なライティングをしていただければと思います。
Langsmith Editor上では、人とシステムの恊働が円滑に進むよう、いくつかの工夫が施されています。また、たくさん案を出されても結局どれを採用すればいいのか悩むという方に対して、このシステムの裏側を知ってもらいながら、判断の拠り所を提供できればと思います。これらの点を以下で解説していきます。
機能
文の一部を選択すると、選択箇所を重点的に言い換えてくれます。例えば以下の例のように、文の前半を選択したときや、動詞を選択した時などで出力が変わります。この機能を使って、どこを重点的に修正して欲しいかシステムに指示しましょう。また、修正案に多様性が生まれるような働きかけをモデルに対して行っています。



特定の箇所の書き換えを指示しても、他の箇所に明らかな誤りがある場合は、そちらの修正を優先する傾向があるようです。またあくまで印象ですが、文が良くなってくるとシステムの提案が軽微なものになってきます。直すところがないと判断されると、修正結果としてグッドマーク?が出ます(これは滅多に出てこないので、グッドマークが出ないからといって心配する必要はありません)。
修正案の取捨選択のコツ
- 基準1: 上に表示されているものを選ぶ
-
出力はより典型的な表現(言語モデルのPerplexity が低いもの)から順に上から並んでいます。並び替えでは前後の文脈も考慮されています。選択に悩んだら、上の方に表示される候補を重点的に考慮すると良いでしょう。
- 基準2:どの案でも書き換えられている箇所について考える
-
たとえシステムの修正案に納得が行かなくても、多くの修正案の中で修正が試みられている表現は、適切でない表現かもしれないと疑うと良いです。
その他Tips
マスクの活用
特定の箇所に入る適切な表現(単語・フレーズ)が知りたい場合は、その箇所に () を挿入してください。()で指定された箇所に表現を補足して修正候補を提案してくれます。この機能は、より広い文脈を考慮した、Key Word in Context型の支援機能(Hyper Collocation 、linggle 、PoEC など)であると考えています。

文章の補完
タブ Keyを押すと、カーソルの地点より左側の文章を考慮して、続きを予測してくれます。また、論文タイトルとセクション名(画像の * Introduction)を考慮しながら補完してくれます。

この機能もHyper Collocation などの支援システムの延長にあると考えています。また、セクション名を指定して補完を連打すると、セクションの書き出しのテンプレートのようなものが得られるため、ちょっとした論の流れのプランニングにも使えるかもしれません。また本機能については、Write With Transformer でも似た体験ができます (ただし、論文タイトルやセクション名似条件づいた生成などはできません) 。
他のツールと組み合わせた活用
辞書やPower Thesaurus のようなサービスを用いて類義表現を探す方も多いと思いますが、ここで見つけた表現を本当に自分が書いている文に当てはめてよいかという判断をするのは難しいです。そこで、類義表現を当てはめた自分の文章をLangsmith Editorに書き、システムによってその表現が重点的に修正されるかを一つの基準として類義表現の採用の是非を決める、という使い方ができると考えています。
また、Overleaf や他のエディタで文章を書く方については、気になる文章をLangsmith Editorにコピー・アンド・ペーストして使うことを想定しています。現在さらに、ブラウザで動くプラグインも開発中です。
なお本システムは、既存の論文に存在する文をコピーして提案することを意図したものでありませんが、偶然他の論文に存在する文と非常に類似した文を提案してしまう事態も考えられます。本システムの使用・不使用に限った話ではありませんが、論文公開前には剽窃チェッカーを使用しましょう。
その他関連ページ
デモ動画も公開していますので、興味があればご覧ください。
またシステムの操作方法については、使い方ページ にもまとまっています。
どんな仕組み?
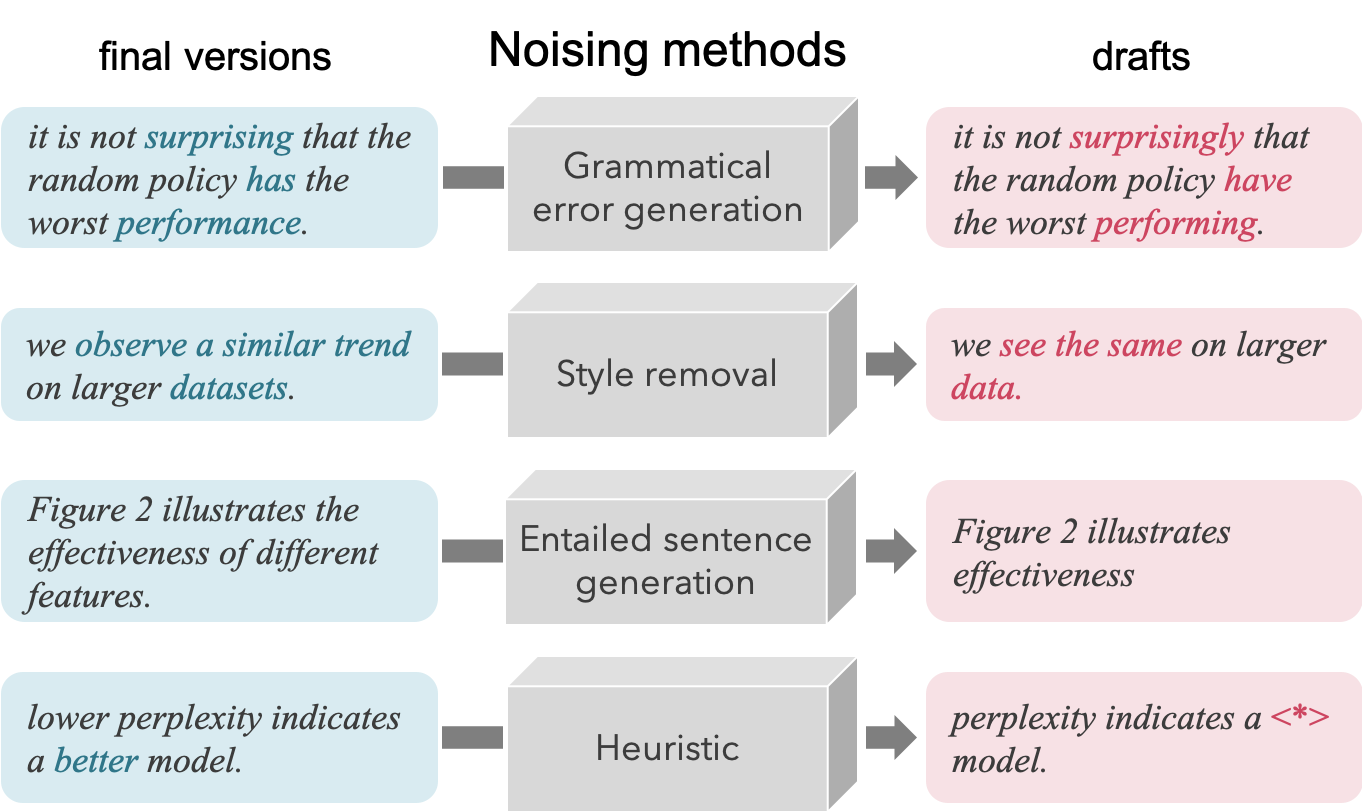
ここまで見てきたとおり、Langsmith Editorは、言い回しに改善の余地がある文に対して修正候補を提示してくれます。この技術は、ニューラル系列変換モデル(系列を入力として受け取り、別の系列へ変換する確率モデル)[1]によって実現しています。このモデルを訓練するためには、大量の入出力の対が必要です。つまり、論文のドラフトと最終稿のペアが必要です。最終稿はACL Anthology やarXiv などの論文アーカイブから容易に手に入る一方で、論文のラフなドラフト・初稿データを手に入れることは困難です。
そこで、機械翻訳・文法誤り訂正などの系列変換系のタスクで主流となっている、データ拡張の手法[2,3,4]を用いて、擬似的な学習データを作成することで本システムを学習しています。例えば、文法誤りを付与する系列変換モデルや言い換えをおこなう系列変換モデルを訓練し、ACL AnthologyやarXivから収拾したテキストにそれらの系列変換モデルでノイズを加えることで、擬似的にドラフトを作成しています。詳細は論文[5]を参照してください。
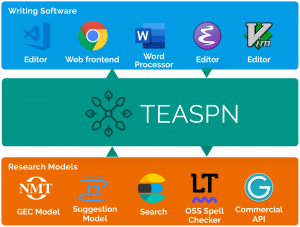
また、TEASPNという言語処理技術とエディタを繋ぐプロトコルをOctanove Labs の萩原さん と開発しました[6]。Langsmith Editorでも、このプロトコルを元にして作成しています。
今後の展望
現在のLangsmith Editorは自然言語処理の論文データから、各モデルを学習しています。今後はより多くの学生や研究者の方に使っていただけるよう、画像処理や生物工学など、より多くのドメインに対応したシステムを開発していきます。また、Langsmithの各技術をより多くのライティングソフトウェアで使用していただけるよう、ブラウザやMicrosoft Wordなどのプラグインを開発中です。
開発の裏側
グループ企業であるエッジインテリジェンス・システムズ株式会社の日高さんにはフロントエンドや、バックエンドの構築でサポートしていただきました。また、乾教授、鈴木教授をはじめ、東北大学 自然言語処理研究室のメンバーには多くの技術的アドバイスやフィードバックをいただきました。